Building an Ecommerce GraphQL API: Our Journey
Shortly after the initial announcement of GraphQL we realized that we can provide a lot of value for our customers by providing a GraphQL-based API for the commercetools platform (CTP). Here I would like to share our journey with you and describe the reasons why we chose GraphQL and how we implemented it alongside our REST API.
Why GraphQL?
From the very beginning the commercetools platform was API-driven and for a while we have been using a RESTful approach to expose it. We put a lot of attention in the design of our resources and their semantics. The resources are modeled based on Domain Driven Design (DDD) principles and patterns. For instance, every resource (like product, order, discount, etc.) represents an aggregate root and generally defines a transactional boundary. As we iterated on our API design based on the user feedback and our own discoveries we faced quite a few challenges which led us to GraphQL and which I would like to share with you in more detail in the next sections.
Over-/Under-fetching
The first challenge is the amount of information we give back to our clients. Let’s look at a typical e-commerce application.

It requires a lot of information to render just a single page. On the other hand we have other clients that do not necessarily need all of this information, but are very limited in terms of number of requests and amount of data they can transfer/process in a reasonable amount of time:

It’s a tough challenge to design a single model and resource structure that would fit the needs of all these different client types. In order to address some of these issues we have introduced reference expansion in our REST API. This helped clients to get most of the needed information in a single request, but still results in huge amount of data over-fetching. For instance some of the bigger projects contain huge products and variants. In these projects just a single product may have several megabytes of data. What makes situation even worse is that most of the clients need only a small portion of this data which is relevant to the application.
Data Access Patterns
Even after we introduced the reference expansion mechanism for all of our resources, there are still a lot of use-cases that require clients to make several consequent API requests because they are unable to fetch all of the necessary information in one go. Given a series of independent client requests it becomes challenging to correlate these requests together and to optimize data retrieving/caching strategy. There is an implicit correlation between many of the requests to our API, but there is no way for a client to communicate this information and help us perform optimizations based on it.
API Evolution
A while back I described some of the challenges of API evolution in this article:
Our API evolves very fast: we learn new things, get feedback from our customers, implement new ideas. It is important for us to keep the pace and change the API without breaking existing API clients.
Unfortunately this is challenging with the RESTful approach. There is no (standard) way for client and server to communicate the deprecation information. So far we did our best to not introduce versioning in our REST API since maintaining different versions would require a lot of maintenance effort and may slow us down.
Documentation & Discovery
At the moment we are maintaining our REST API documentation in a set of static markdown files. These markdown files are external to the code and it is pretty tedious to keep documentation in sync with the actual API.
I strongly believe that modern API documentation should not only provide structured information, but also be interactive. Ideally new API users should be able to discover API capabilities as they make requests in an iterative environment.
We looked at RAML and Swagger and made several proofs of concept. After evaluating these tools we still could not find a consensus on which tools we should use and which approach will require the least maintenance.
Even though these tools do provide an ability to document the API in a structured way, one still needs to manage it externally. JSON schema also does not map very smoothly in the way we structure and define our API. We also faced quite a few issues with different tools around JSON schema, which didn’t make our decision easier. There are a number of API consoles available for RAML and Swagger, but in my opinion, none of them provide the same degree of interactivity and polish as GraphiQL.
Discovering GraphQL
GraphQL helped us address these challenges. The request/response cycle of a typical GraphQL query looks very similar to normal HTTP GET or POST request:
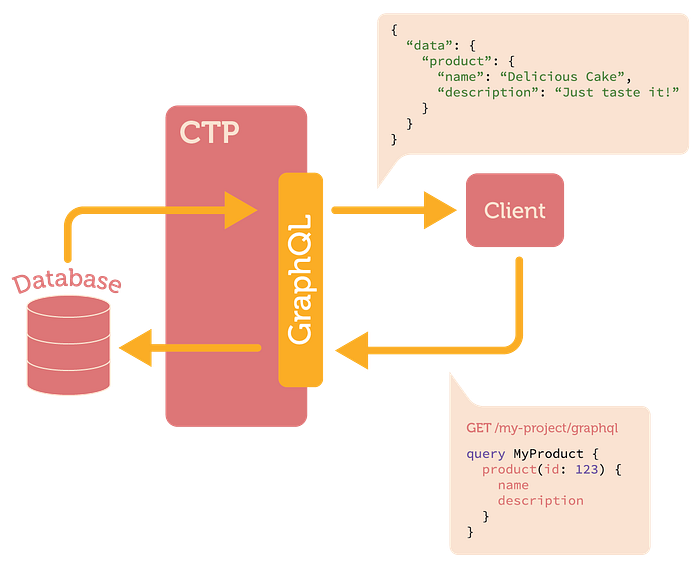
In this example the client asks a server for a name and description of a particular product. And this is precisely what the server gives back to the client in it’s response.
I will not go into detail on the GraphQL basics in this article, there are a lot of resources already available on this topic. Instead I would like to focus on how it helped us building our API and address challenges that I described earlier.
One can see a GraphQL query as a way for a client to communicate its data requirements:
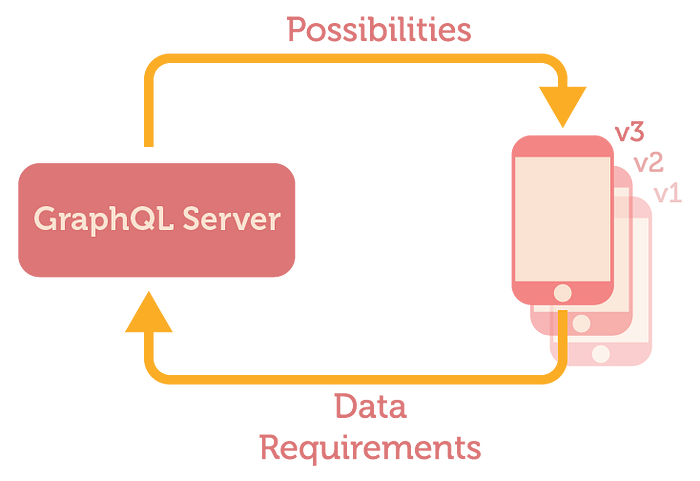
Which also means that one can treat different versions of the same client application as different application with slightly different data requirements. GraphQL itself provides a native way of deprecating fields and communicating this deprecation information to the client. The client, on the other hand, is always required to specify its data requirements in form of a GraphQL query. This provides us with a way to evolve our API very naturally without breaking existing clients or resorting to versioning.
On the server we always know which objects and fields existing clients are still actively using. If we decide to remove or change existing fields, we can go through a deprecation process where we first deprecate existing fields, wait until all clients are migrated, and then remove these fields with confidence.
By its nature, GraphQL addresses issues with under-/over-fetching of the data. Project data is no longer available as a set of independent resources, but instead represented as an object graph. This not only provides a very natural data model for a client, but also allows it to fetch all necessary information for a particular view or bit of business logic in one request. At the end of the day it’s all about making colleagues, who are using your API, happy ;)
In this particular case we exposed product categories in our GraphQL API. It is an interesting scenario because both server and client benefit greatly from using the GraphQL API. After the new feature was shipped, the client was able to fetch several levels of categories with product counts with a single GraphQL query like this one:
{
categories {
results {
name(locale: "en")
productCount
children {
name(locale: "en")
productCount children {
name(locale: "en")
productCount
}
}
}
}
}
The server, on the other hand, does not receive all these 150 independent requests anymore. Instead it gets only one single request with a GraphQL query that describes very precisely the client intention and requirements. Just by having this information we are able to optimize our internal queries to MongoDB and Elasticsearch and retrieve the requested three levels of categories very efficiently.
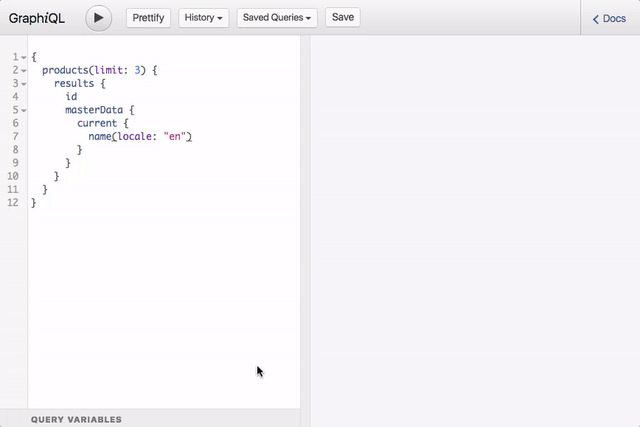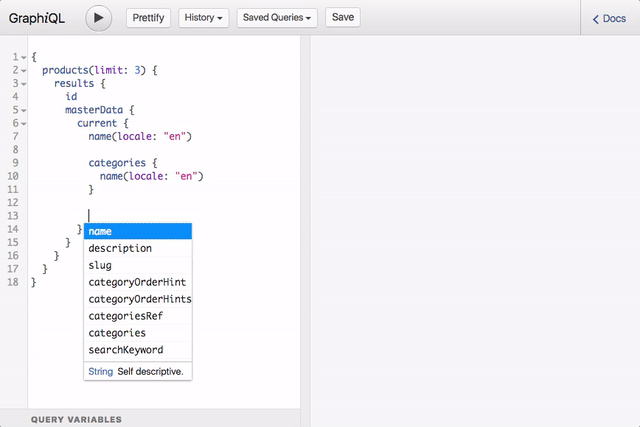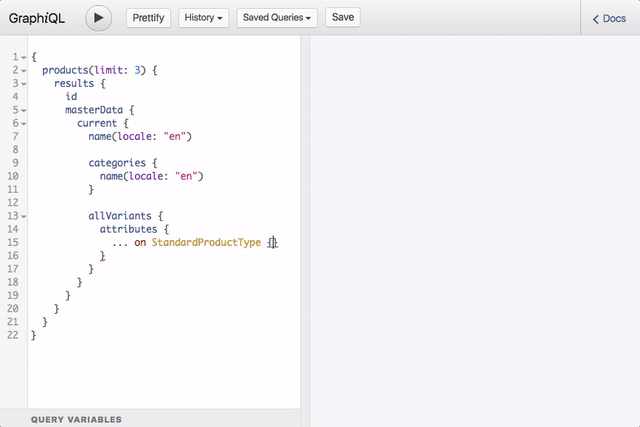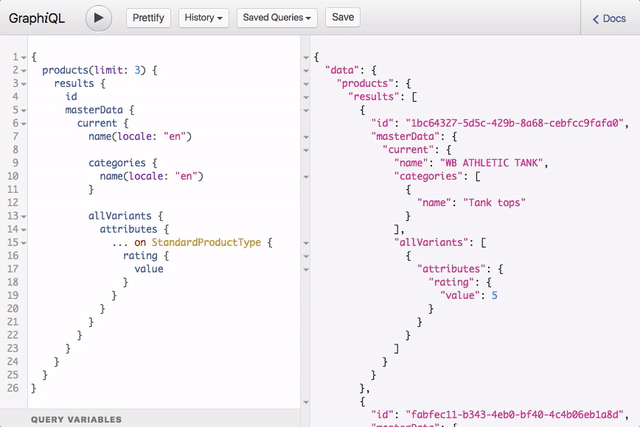
In terms of documentation and discovery GraphQL has a lot to offer as well. The type system and introspection API provide all of the necessary information to generate structured documentation and build tools that help users discover and learn an API. I think this demonstration of GraphiQL tool speaks for itself:
The GraphQL provided us with a very compelling set of tools to overcome the challenges we faced with the REST API. The journey to GraphQL was not without challenges on its own, though.
Stay tuned for a second part of this article where we will go into detail on challenges we faced as we were implementing the GraphQL API and the way we addressed them.

